Échantillonnage aléatoire stratifié
Qu’est-ce que l’échantillonnage aléatoire stratifié?
L’échantillonnage aléatoire stratifié est une méthode d’échantillonnage qui implique la division d’une population en sous-groupes plus petits appelés strates. Dans l’échantillonnage aléatoire stratifié ou la stratification, les strates sont formées sur la base d’attributs ou de caractéristiques communs aux membres, tels que le revenu ou le niveau d’instruction.
NB: L’échantillonnage stratifié est utilisé pour mettre en évidence les différences entre les groupes d’une population, par opposition à l’échantillonnage aléatoire simple, qui considère tous les membres d’une population comme égaux, avec une probabilité égale d’être échantillonnés.
Comment fonctionne l’échantillonnage aléatoire stratifié
En effectuant une analyse ou une recherche sur un groupe d’entités présentant des caractéristiques similaires, un chercheur peut constater que la taille de la population est trop importante pour permettre de mener à bien une recherche. Pour gagner du temps et de l’argent, un analyste peut adopter une approche plus réaliste en sélectionnant un petit groupe dans la population. Le petit groupe est appelé la taille de l’échantillon, qui est un sous-ensemble de la population utilisé pour représenter la population entière. Un échantillon peut être sélectionné dans une population de différentes manières, notamment la méthode d’échantillonnage aléatoire stratifié.
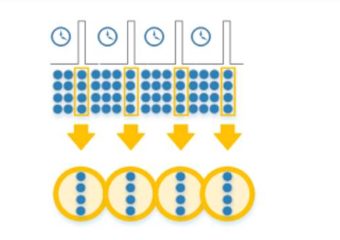
Un échantillonnage aléatoire stratifié consiste à diviser la population entière en groupes homogènes appelés strates. Des échantillons aléatoires sont ensuite sélectionnés dans chaque strate. Prenons l’exemple d’un chercheur universitaire qui aimerait connaître le nombre d’étudiants au MBA en 2007 ayant reçu une offre d’emploi dans les trois mois suivant l’obtention de leur diplôme.
Il découvrira bientôt qu’il y avait près de 200 000 diplômés du MBA pour l’année. Il pourrait décider de ne prendre qu’un échantillon aléatoire simple de 50 000 diplômés et de mener une enquête. Mieux encore, il pourrait diviser la population en strates et prélever un échantillon aléatoire des strates. Pour ce faire, il créerait des groupes de population basés sur le genre, la tranche d’âge, la race, le pays de nationalité et le parcours professionnel. Un échantillon aléatoire de chaque strate est pris en nombre proportionnel à la taille de la strate par rapport à la population. Ces sous-ensembles des strates sont ensuite regroupés pour former un échantillon aléatoire.
Retenons
- L’échantillonnage aléatoire stratifié permet aux chercheurs d’obtenir un échantillon de population qui représente le mieux l’ensemble de la population étudiée.
- L’échantillonnage aléatoire stratifié consiste à diviser la population entière en groupes homogènes appelés strates.
- L’échantillonnage aléatoire stratifié diffère de l’échantillonnage aléatoire simple, qui implique la sélection aléatoire de données provenant d’une population entière, de sorte que chaque échantillon possible a la même probabilité de se produire.
Exemple d’échantillonnage aléatoire stratifié
Les chercheurs et les statisticiens utilisent un échantillonnage aléatoire stratifié pour analyser les relations entre deux strates ou plus. Comme l’échantillonnage aléatoire stratifié implique plusieurs couches ou strates, il est essentiel de calculer les strates avant de calculer la valeur de l’échantillon.
Voici un exemple classique d’échantillonnage aléatoire stratifié:
Disons que 100 (N h) élèves d’une école comptant 1 000 (N) élèves ont été interrogés sur leur matière préférée. C’est un fait que les élèves de la 8e année auront des préférences de matière différentes de celles des élèves de la 9e année. Pour que l’enquête fournisse des résultats précis, l’idéal est de diviser chaque note en différentes couches.
Voici un tableau du nombre d’élèves dans chaque classe:
| Classe | Nombre d’étudiants (n) |
| 5 | 150 |
| 6 | 250 |
| 7 | 300 |
| 8 | 200 |
| 9 | 100 |
Calculez l’échantillon de chaque classe en utilisant la formule d’échantillonnage aléatoire stratifié:
| Échantillon stratifié (n5)= 100/1000 * 150 = 15 |
| Échantillon stratifié (n6)= 100/1000 * 250 = 25 |
| Échantillon stratifié (n7)= 100/1000 * 300 = 30 |
| Échantillon stratifié (n8)= 100/1000 * 200 = 20 |
| Échantillon stratifié (n9)= 100/1000 * 100 = 10 |
Échantillons aléatoires simples ou aléatoires stratifiés
Les échantillons aléatoires simples et les échantillons aléatoires stratifiés sont tous deux des outils de mesure statistique. Un échantillon aléatoire simple est utilisé pour représenter l’ensemble de la population de données. Un échantillon aléatoire stratifié divise la population en groupes plus petits, ou strates, en fonction de caractéristiques communes.
L’échantillon aléatoire simple est souvent utilisé lorsqu’il y a très peu d’informations disponibles sur la population de données, lorsque la population de données présente trop de différences pour être divisée en divers sous-ensembles ou lorsqu’il n’existe qu’une seule caractéristique distincte parmi la population de données.
Par exemple, une entreprise de fabrication de bonbons peut vouloir étudier les habitudes d’achat de ses clients afin de déterminer l’avenir de sa gamme de produits. S’il y a 10 000 clients, il peut utiliser 100 de ces clients comme échantillon aléatoire. Il peut ensuite appliquer ce qu’il trouve parmi ces 100 clients au reste de sa base. Contrairement à la stratification, 100 membres seront choisis au hasard, sans tenir compte de leurs caractéristiques individuelles.
Stratification proportionnelle et disproportionnée
Un échantillonnage aléatoire stratifié garantit que chaque sous-groupe d’une population donnée est correctement représenté dans l’ensemble de la population de l’échantillon d’une étude. La stratification peut être proportionnée ou disproportionnée. Dans l’échantillonnage stratifié proportionnel, la taille de l’échantillon de chaque strate est proportionnelle à la taille de la population de la strate.
Par exemple, si le chercheur souhaitait un échantillon de 50 000 diplômés utilisant la tranche d’âge, l’échantillon aléatoire stratifié proportionnel serait obtenu à l’aide de la formule suivante: (taille de l’échantillon / taille de la population) x taille de la strate. Le tableau ci-dessous suppose une population de 180 000 diplômés du MBA par an.
| Tranche d’âge | 24-28 | 29-33 | 34-37 | Total |
| Nombre de personnes dans la strate | 90 000 | 60 000 | 30 000 | 180 000 |
| Taille de l’échantillon dans la strate | 25 000 | 16 667 | 8 333 | 50 000 |
La taille de l’échantillon de strates pour les diplômés du MBA âgés de 24 à 28 ans est calculée comme suit: (50 000/180 000) x 90 000 = 25 000. La même méthode est utilisée pour les autres groupes d’âge. Maintenant que la taille de l’échantillon de strates est connue, le chercheur peut effectuer un échantillonnage aléatoire simple dans chaque strate afin de sélectionner les participants à son enquête. En d’autres termes, 25 000 diplômés du groupe d’âge des 24 à 28 ans seront choisis au hasard parmi l’ensemble de la population, 16 667 diplômés du groupe des 29 à 33 ans seront sélectionnés au hasard dans la population, et ainsi de suite.
Dans un échantillon stratifié disproportionné, la taille de chaque strate n’est pas proportionnelle à sa taille dans la population. Le chercheur peut décider d’échantillonner la moitié des diplômés du groupe des 34 à 37 ans et le tiers des diplômés du groupe des 29 à 33 ans.
Il est important de noter qu’une personne ne peut pas appartenir à plusieurs strates. Chaque entité ne doit appartenir qu’à une seule strate. Le chevauchement des sous-groupes signifie que certaines personnes auront plus de chances d’être sélectionnées pour l’enquête, ce qui annule complètement le concept d’échantillonnage stratifié en tant que type d’échantillonnage probabiliste.
NB: les gestionnaires de portefeuille peuvent utiliser un échantillonnage aléatoire stratifié pour créer des portefeuilles en répliquant un indice tel qu’un indice obligataire.
Avantages de l’échantillonnage aléatoire stratifié
L’ échantillonnage aléatoire stratifié a pour principal avantage de saisir les principales caractéristiques de la population de l’échantillon. Semblable à une moyenne pondérée, cette méthode d’échantillonnage produit des caractéristiques dans l’échantillon proportionnelles à la population globale. L’échantillonnage aléatoire stratifié fonctionne bien pour les populations avec une variété d’attributs mais est autrement inefficace si des sous-groupes ne peuvent pas être formés.
La stratification donne une erreur d’estimation plus petite et une plus grande précision que la méthode d’échantillonnage aléatoire simple. Plus les différences entre les strates sont grandes, plus le gain de précision est grand.
Inconvénients de l’échantillonnage aléatoire stratifié
Malheureusement, cette méthode de recherche ne peut être utilisée dans toutes les études. L’inconvénient de la méthode est que plusieurs conditions doivent être remplies pour une utilisation correcte. Les chercheurs doivent identifier chaque membre de la population étudiée et classer chacun d’entre eux en une et une seule sous-population. En conséquence, l’échantillonnage aléatoire stratifié est désavantageux lorsque les chercheurs ne peuvent pas classer avec certitude chaque membre de la population dans un sous-groupe. En outre, il peut être difficile de trouver une liste exhaustive et définitive de toute une population .
Le chevauchement peut être un problème si certains sujets appartiennent à plusieurs sous-groupes. Lorsqu’un échantillonnage aléatoire simple est effectué, ceux qui appartiennent à plusieurs sous-groupes ont plus de chances d’être choisis. Le résultat pourrait être une fausse représentation ou un reflet inexact de la population.



Très simple, pratique et même « Toto » peut le comprendre.
C’est assez plus clair que dans les amphithéâtres.
Merci à vous